Last week we introduced the Machine Learning (ML) lifecycle - or, every stage that is followed (and re-followed) in best practice ML projects. It’s important to remember that this isn’t a measure to guarantee success against your starting criteria - but rather to ensure that your initiative is carried out in such a way that the best possible results will be achieved.
First let's recap on what the lifecycle looks like:
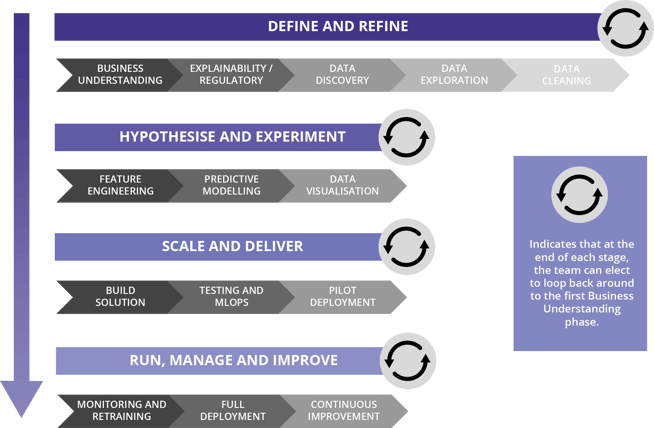
Always bear in mind that every stage is iterative and many projects, however far along the ladder they are, will end up looping back to the start for all sorts of different reasons - whether it's a case of bailing entirely or just slightly refining to get better results.
We can now think about these in terms of the four main stages.
Define and Refine
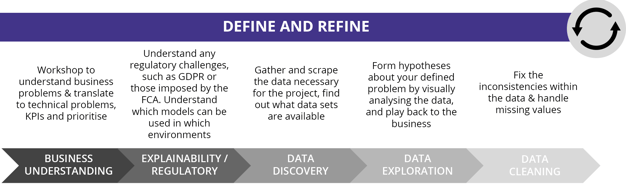
You can't overstate how crucial getting Define and Refine right is. Often, ML initiatives can struggle to even leave this loop, and ones that don't treat every step with diligence are more often than not setting up for later failure.
It's not uncommon for projects to repeatedly iterate back to the Business Understanding phase, even those that have made it as far as Run, Manage and Improve. It might be that further down the line the right results aren't being generated, and that a different approach needs to be evaluated. It might also be that as the business continues to change, so do the parameters the ML project needs to work within.
Hypothesise and Experiment
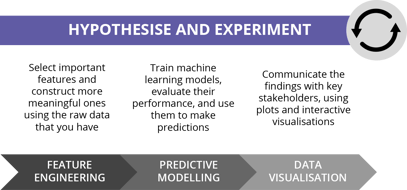
In previous blogs we've covered the importance of breaking down the barriers between different units within the organisation, such as data teams and business teams. In this phase it's particularly critical to focus on those communication channels.
This way we're able to carry on in the true spirit of data science and continually hypothesise and experiment, while keeping that constant feedback loop with stakeholders active so we're being as efficient as possible - and more vitally, so we're staying on track with the objectives of the project.
For example, if stakeholders don't consider the findings at this stage to be of much value, then the whole ML exercise isn't working and needs to loop back, either to the start of this major phase, or to the start of Define and Refine. We need to make sure that we're continually adding business value.
Scale and Deliver
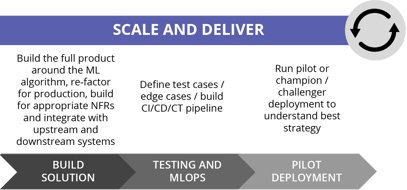
There are options in the Scale and Deliver phase, such as whether to adopt a pilot or a champion / challenger approach. Again, this will vary on the business so it's important to keep communications regular.
Utilising MLOps - the convergence of ML and operations teams - is crucial to ensuring that the delivery is as effective and efficient as possible. We covered this in an earlier blog if you want to learn more about why this matters and the best ways to implement.
Run, Manage and Improve
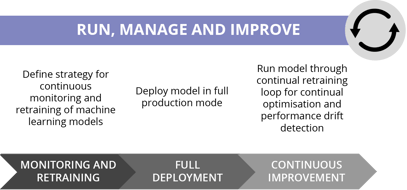
Target variables also change over time. For example, when it comes to the detection of fraudulent transactions (which is a very useful real-world application of ML), behaviours change with time, which can include criminals adopting increasingly sophisticated methods of committing fraud.
As part of the continuous improvements, detecting and then accounting for this performance drift - again, by staying closely aligned to the business stakeholders - will help your models drive as much value as possible.
Of course, even at this stage it's entirely possible that you will have to loop right back to looking at the business understanding again. Therefore the best mindset is to treat the entire lifecycle as continually in flux, as we're fundamentally using machine learning to respond to a world that keeps changing rapidly.
Don't forget to subscribe below to kept up-to-date with the latest on data & machine learning!
The Analytics Revolution blog series:

Ethical AI is not an Afterthought

The Machine Learning Lifecycle

Five Recommendations for the Successful Adoption of Machine Learning

CI/CD/CT - DevOps for Machine Learning and Best Practice in Production

Dataflow - Google Cloud's Best-Kept Secret